Python Django Web Scraping

In this tutorial we are going to look at how we can extract data from other websites using Beautiful Soup. we are going to get most popular movies from this website below
https://www.imdb.com/chart/moviemeter/
If you go to that website you will see a list of most popular movies
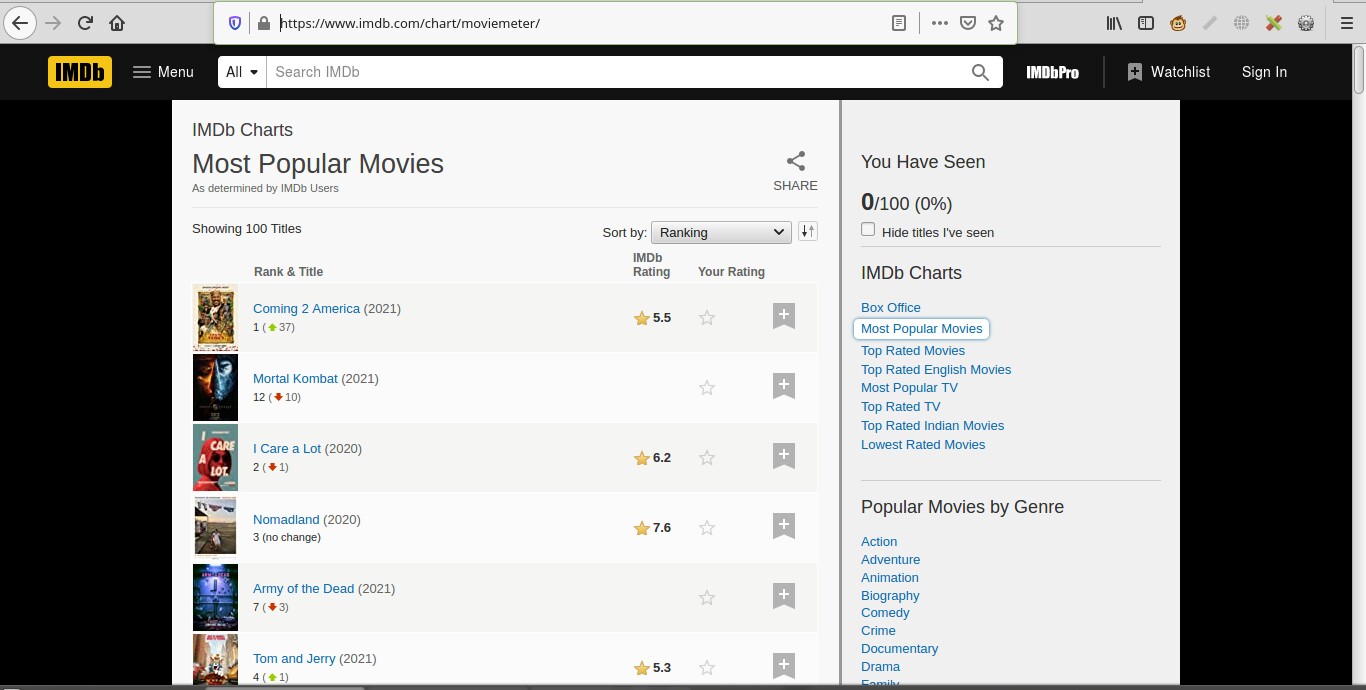
We will write a python program that will extract this information.
First of all install requests and BeautifulSoup using the following commands
pip install requests
pip install beautifulsoup4
If you inspect this page you will realize that all these movies are contained in a table with a class of chart full-width
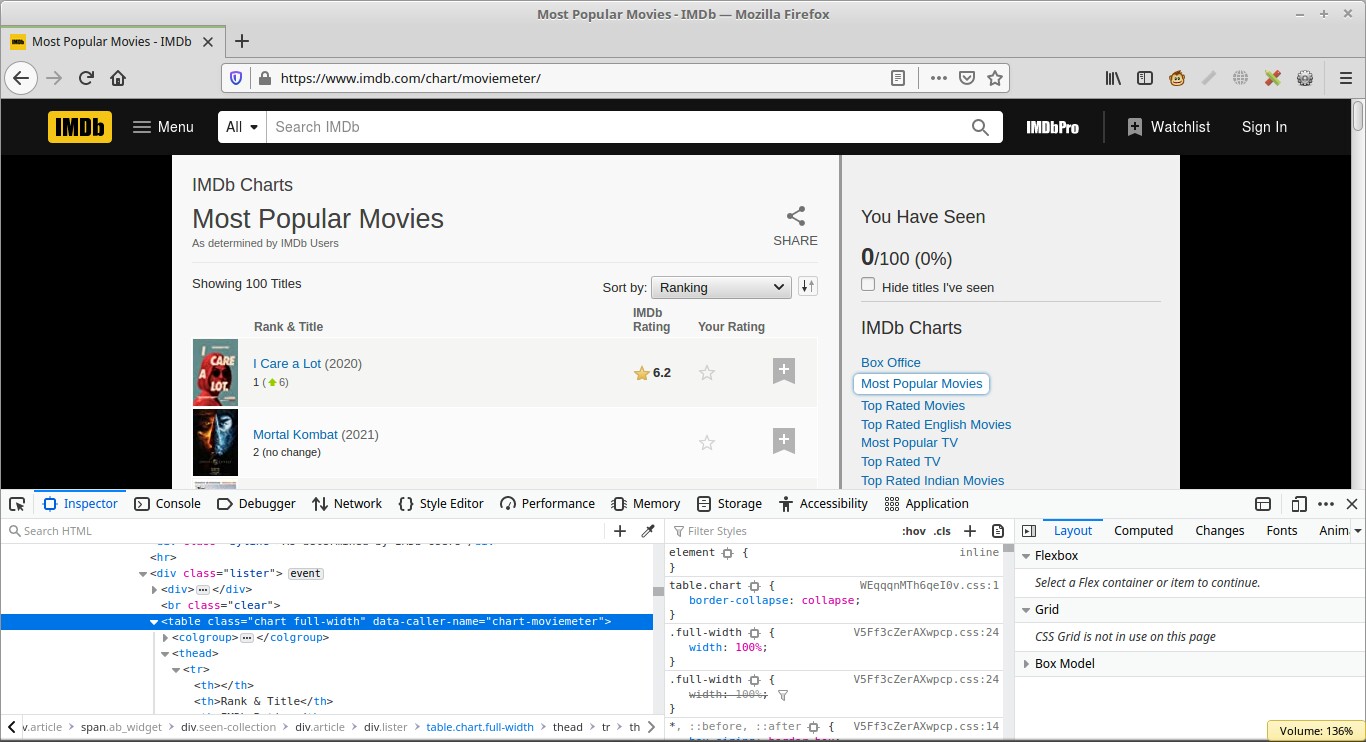
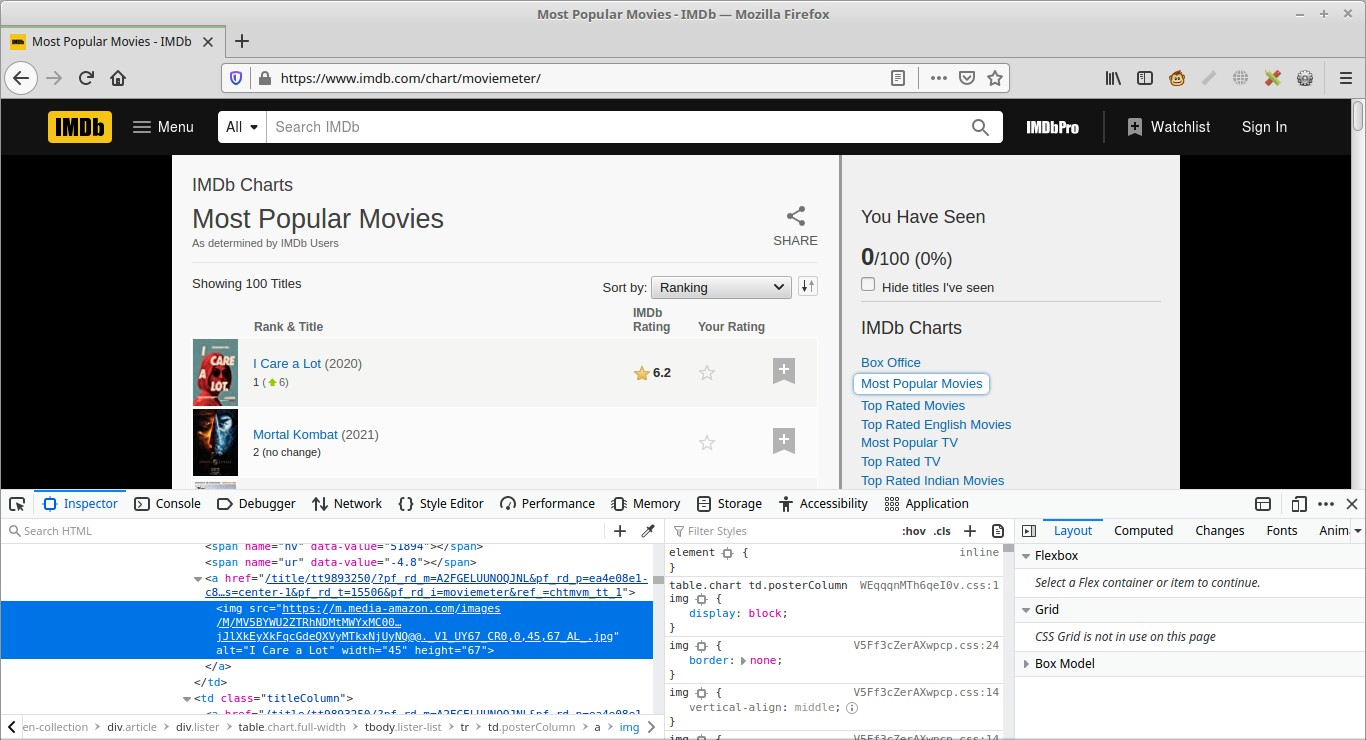
Now lets inspect the image besides the movie title by right clicking on it and clicking inspect , you will see that the title of the movie is found in the alt attribute of the image. This is what we are going to get with our python program.
Our complete python program will look like this
import requests
from bs4 import BeautifulSoup
url = "https://www.imdb.com/chart/moviemeter/"
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
table = soup.find('table', {'class': 'chart full-width'})
rows = table.find_all('tr')
movies = []
for row in rows:
image = row.find('img')
if image:
movies.append(image['alt'])
The above program does the following , it goes to this page "https://www.imdb.com/chart/moviemeter/" and it looks for a table with a class of chart full-width and then we find all the images in the rows of this table , after that we get the alt attribute of these images which contain the movie title that we need.
After we extract the movie titles , we append them to the movies list and now we can use django to display this list like this
def home(request):
url = "https://www.imdb.com/chart/moviemeter/"
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
table = soup.find('table', {'class': 'chart full-width'})
rows = table.find_all('tr')
movies = []
for row in rows:
image = row.find('img')
if image:
movies.append(image['alt'])
return render(request, "movies/home.html", {'movies': movies})
On the html side our list will be displayed like this
{% extends 'base.html' %}
{% block content %}
<div class="container">
<h1 class='text-center'> Movies List </h1>
<div class="row">
<div class="col-sm-8 offset-sm-2">
<ul class="list-group">
{% for movie in movies %}
<li class="list-group-item">
<p>{{ movie }}</p>
</li>
{% endfor %}
</ul>
</div>
</div>
</div>
{% endblock %}
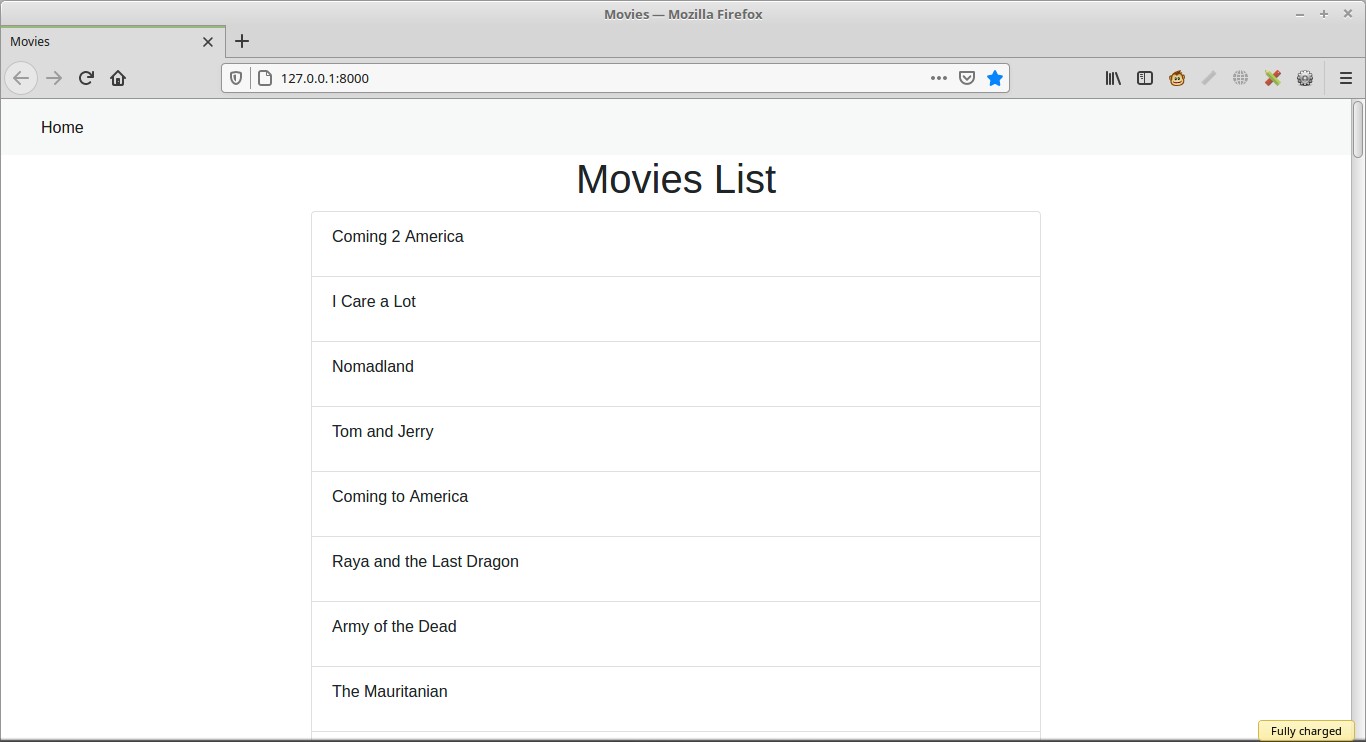
Our Django app will now display the movies list as shown in image below, remember this list was extracted from another website and now it is being shown in our app.
GET SOURCE CODE
https://github.com/felix13/djangowebscraper
Conclusion
We just created a web scraper to get a list of popular movies from the imdb site, Now feel free to modify this scraper to scrape other things on the internet, this could be prices of products in other websites or information from wikipedia.
Keep Learning
- What is super() in python
- Understand clean() and clean_<fieldname>() in Django
- Simple Pagination in Django